Daten & KI im Arbeitsmarkt 2026 - Österreich
Von Aloisious CaraetLetztes Update: 25 Juni 202613 min Lesezeit
Mit:
- data:unplugged

Gemeinsam mit data:unplugged haben wir 24.892 offene Stellenanzeigen in Österreich ausgewertet (Stand 1. Mai 2026) und jene 1.113 Anzeigen mit Daten- und KI-Anforderungen im Detail unter die Lupe genommen. Daraus ist der Daten- & KI-Report 2026 entstanden – ein Blick darauf, welche Fähigkeiten der österreichische Arbeitsmarkt von morgen wirklich verlangt.
Wer an KI-Jobs denkt, denkt an den Data Scientist. Tatsächlich trägt nur ein kleiner Teil der Daten- und KI-Stellen einen solchen Titel – der Großteil bleibt auf dieser Ebene unsichtbar. Von 1.113 untersuchten Daten- und KI-Stellen in Österreich tragen lediglich 110 (9,9 Prozent) einen explizit datenwissenschaftlichen oder KI-spezifischen Titel wie Data Engineer, Data Scientist, BI/Analytics Engineer, Data Analyst oder Machine Learning Engineer. Die übrigen 1.003 Stellen – rund 90 Prozent – tragen "konventionelle" Jobtitel. Sie heißen Senior Software Engineer, Controller, Berater:in oder Backend Developer.
"Wer ausschließlich nach "Data Scientist" oder "AI Engineer" filtert, übersieht 90 Prozent des KI-Arbeitsmarktes. Die KI-Karriere beginnt heute selten mit einem Titelwechsel – sie entsteht durch die Anreicherung des bestehenden Berufsbildes."
Aloisious Caraet
Principal Data Scientist Nejo
Inhaltlich verlangen sie Python, SQL, Cloud-Plattformen, Machine-Learning-Verfahren oder MLOps-Praktiken – also exakt jene Kompetenzen, die noch vor wenigen Jahren ausschließlich spezialisierte Daten- und KI-Fachkräfte beherrschen mussten. Ob eine Anzeige als Daten- oder KI-Stelle zählt, entschied dabei nicht die bloße Erwähnung einer Technologie wie Python oder SQL, sondern der inhaltliche Kern der Stelle: Maßgeblich ist, ob die beschriebenen Tätigkeiten tatsächlich Daten- oder KI-Arbeit umfassen. Die 1.003 "versteckten" Profile sind also nicht etwa klassische Software- oder Reporting-Rollen, die Python im Anforderungskatalog tragen, sondern Stellen, deren inhaltlicher Kern in Daten- oder KI-Aufgaben liegt, lediglich unter anderem Namen ausgeschrieben.
Daten- und KI-Arbeit verbirgt sich am Arbeitsmarkt bereits in den unterschiedlichsten Berufen. Die beiden Berufe mit den häufigsten Anforderungen an KI- und Daten-Skills sind der Software Engineer – hier gilt es zunehmend Fähigkeiten wie AWS, Java und Docker dezidiert im KI-Kontext einzusetzen – und der Controller, dessen klassische Finanzfunktion sich zur systematischen Datenanalyse verschiebt.
Am Ende dieses Beitrags kannst du den Daten- & KI-Report 2026 Österreich kostenlos als PDF herunterladen, mit allen Charts und der vollständigen Methodik.
Die DAISY-Ontologie unterscheidet drei Skill-Typen: Tools (konkrete Software, Plattformen, Sprachen), Wissen (konzeptionelle Anforderungen) und Praktiken (Arbeitsweisen, Methoden, Vorgehensmodelle). Die folgenden Top-10-Listen zeigen jeweils die häufigsten Anforderungen pro Kategorie, ergänzt um eine eigene Aufstellung der Top-10-Programmiersprachen als Unterkategorie der Tools.
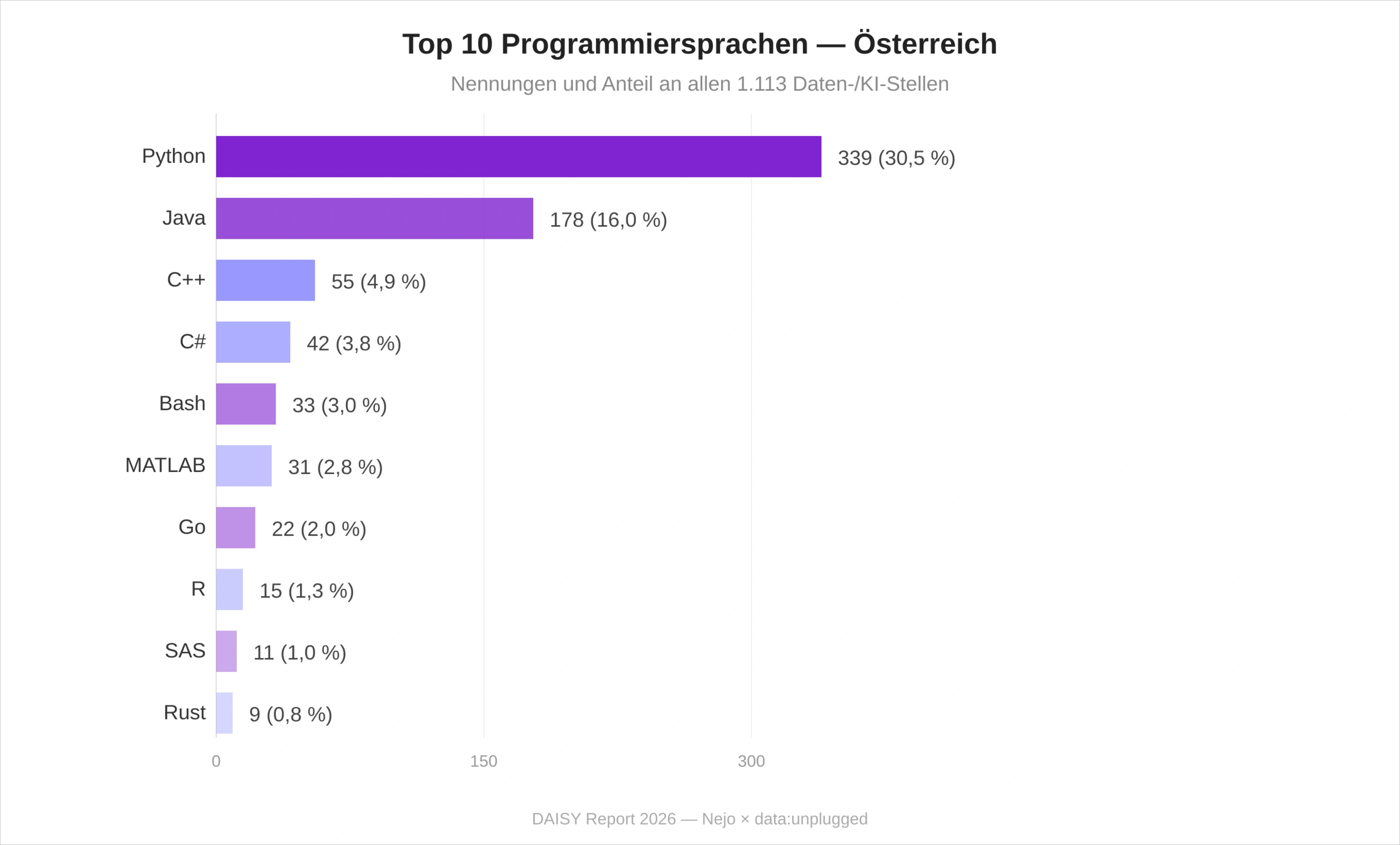
Python dominiert mit 30,5 Prozent, der Abstand zu SQL (Rang 2) ist allerdings kleiner als im deutschen Vergleichsmarkt. Bemerkenswert ist die Position von Java auf Rang 3 (178 Nennungen) – vor Kubernetes, Azure und AWS. Österreichs Daten- und KI-Stack trägt deutlich die Handschrift der Banken- und Enterprise-IT, die Java weiterhin als Kernsprache erhält. Azure (Rang 5, 10,2 Prozent) liegt vor Amazon Web Services (Rang 8, 9,3 Prozent) – ein interessantes Muster, das im Folgekapitel zur Cloud-Infrastruktur weiter ausgeführt wird.
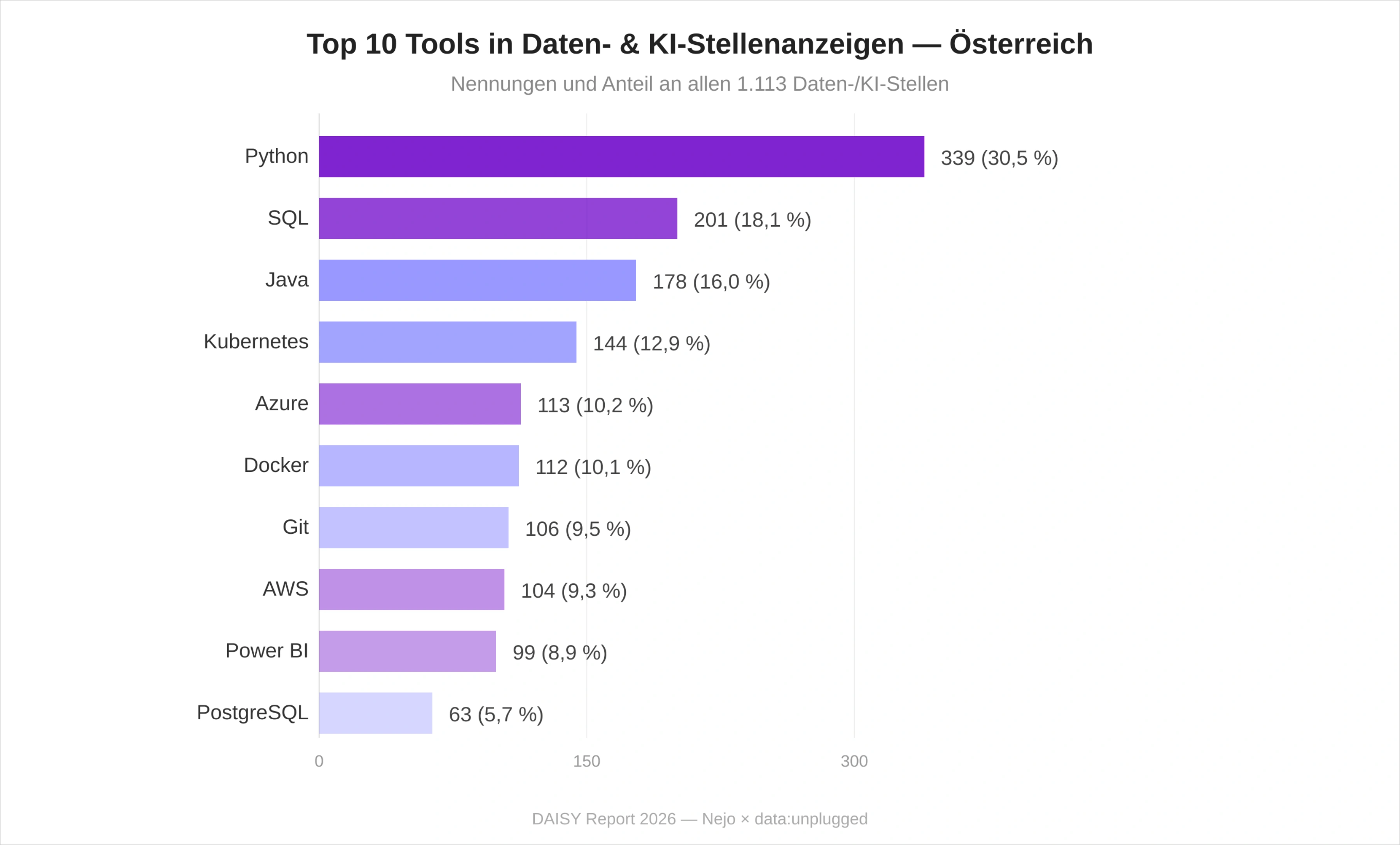
Das Wissenskonzept "Artificial Intelligence" führt die Liste klar an – Arbeitgeber verlangen zunehmend konzeptionelles KI-Verständnis als eigenständige Anforderung. Data Engineering auf Rang 2 zeigt einen weiteren infrastrukturellen Schwerpunkt des österreichischen Marktes. Bereits auf Platz 3 wird ein konzeptionelles Verständnis von KI-Tools und -Assistenten wie ChatGPT & co gefragt – noch vor dem spezialisierteren Bereich des Machine Learnings.
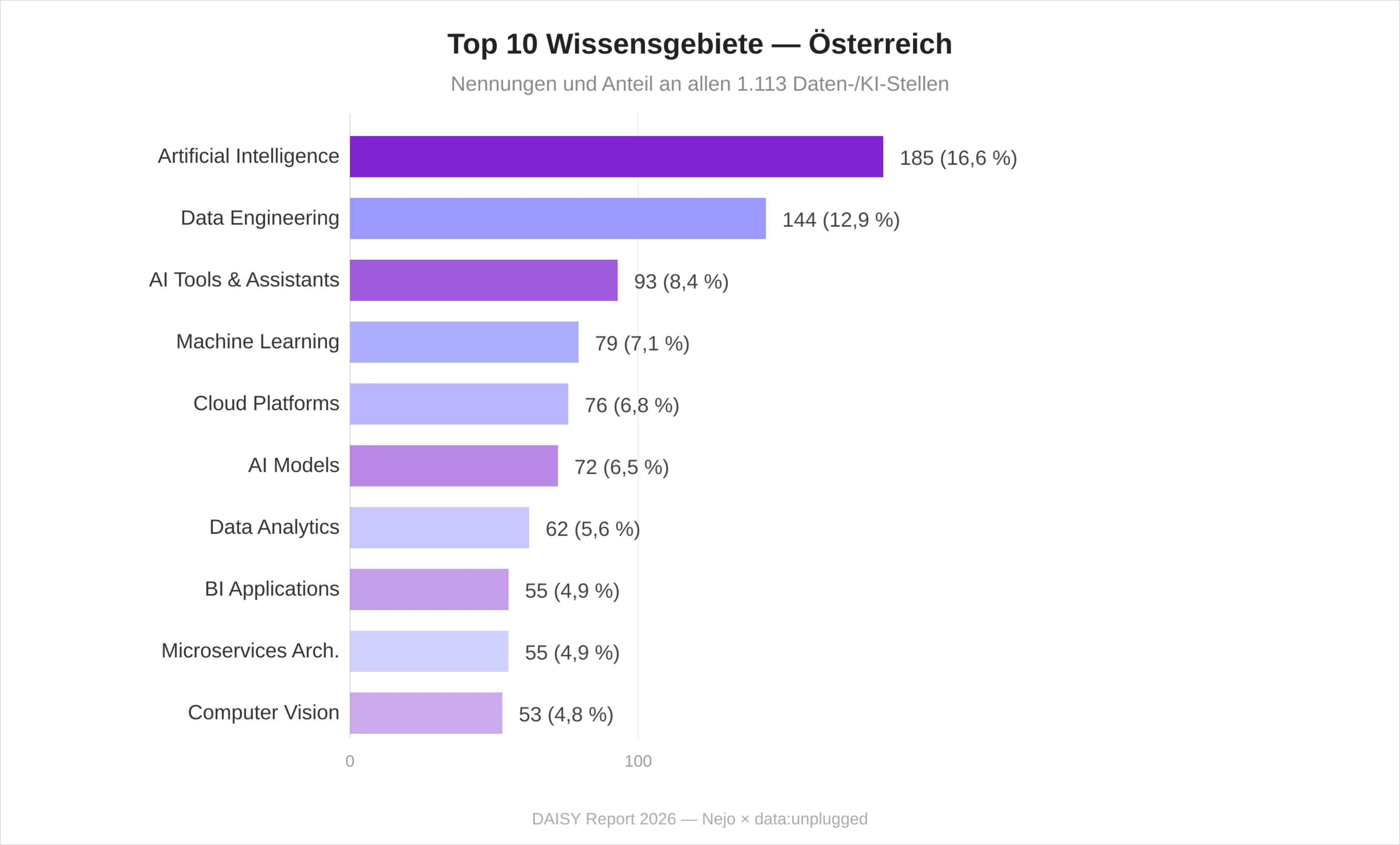
DevOps führt mit 17,1 Prozent – höher als im deutschen Vergleichsmarkt. Auslieferungsdisziplin und Plattform-Praxis prägen den österreichischen Daten- und KI-Stack stärker als reine Machine-Learning-Praktiken. Bemerkenswert ist auch die hohe Bedeutung statistischer Praktiken (Modeling & Testing, Statistical Analysis): Sie zeigen, dass klassische datenwissenschaftliche Methoden ein wichtiger Bestandteil der Skill-Anforderungen in Österreich sind.
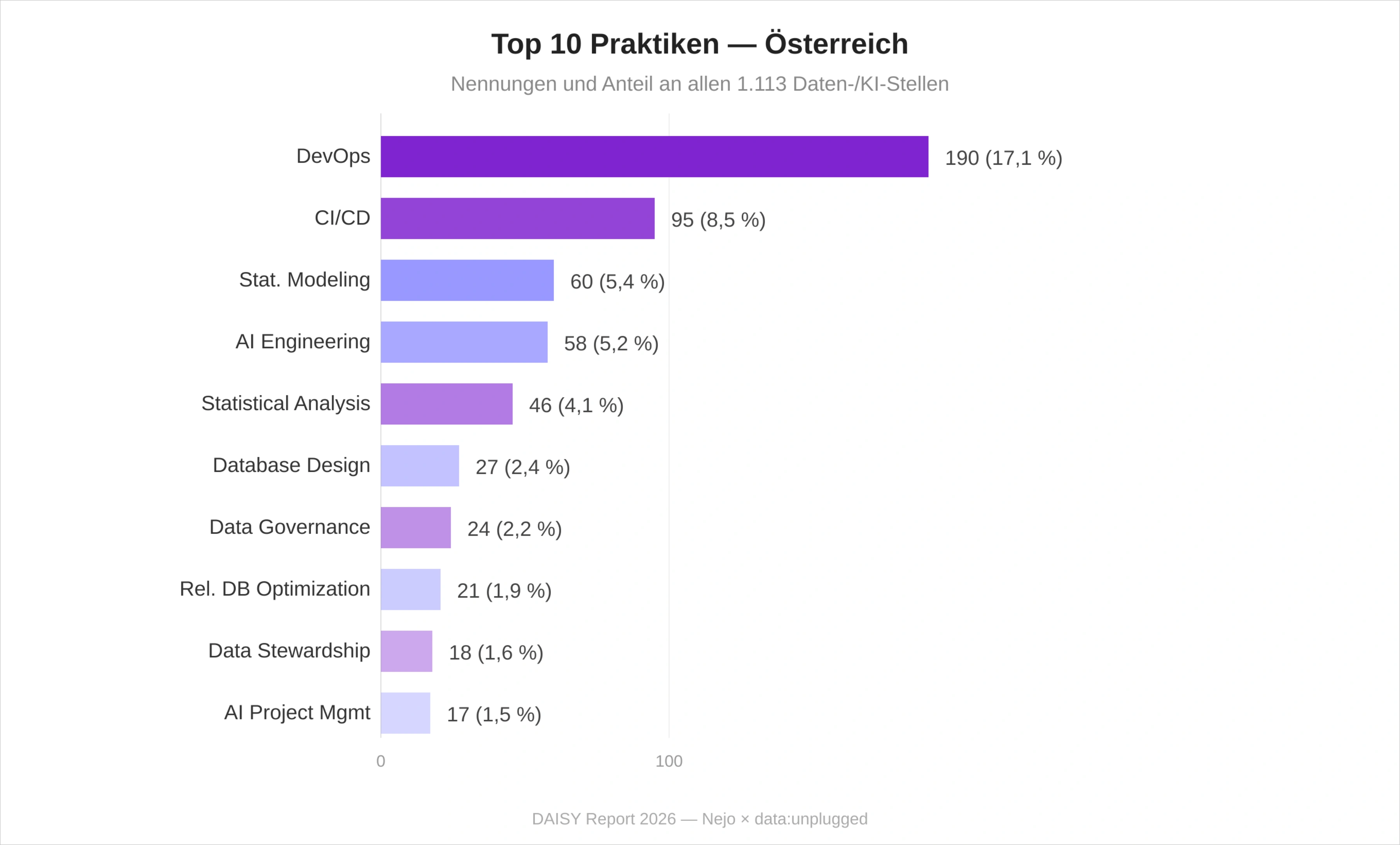
Python übertrifft Java um den Faktor 1,9 – deutlich weniger als der Faktor 3,2 im deutschen Vergleichsmarkt. Java behauptet sich in Österreich als zweitstärkste Sprache, getragen von Banken und Enterprise-Software-Anbietern. C# (Rang 4) ist proportional stärker als in vielen anderen europäischen Märkten – Microsoft-Stack-Affinität reicht auch in die Entwicklungs-Sprache hinein.
Wie im deutschen Vergleichsmarkt sind mehr als die Hälfte aller Anforderungen toolbezogen und damit durchaus konkret. Zusätzlich zur Typisierung (Tool, Wissen, Praktik) ordnet die DAISY-Ontologie jeden Skill einer von sechs übergeordneten Daten- und KI-Domänen zu. Diese Domänen beschreiben das fachliche Anwendungsfeld eines Skills – etwa, ob er der Dateninfrastruktur, der Modellentwicklung oder der generativen KI dient.
Hinter der reinen Werkzeugliste steht zunehmend konzeptionelles Verständnis: Fast die Hälfte aller Skill-Nennungen entfällt nicht auf konkrete Tools, sondern auf Wissensgebiete (29,4 Prozent) und Methoden (16,8 Prozent). "Künstliche Intelligenz" als Konzept zählt dabei zu den fünf meistgenannten Skills überhaupt.
"Unternehmen suchen aktuell vor allem konzeptionelle Fähigkeiten, und erst zweitrangig nach spezifischen Tool-Kenntnissen. Gefragt ist, wer Daten- und KI-Konzepte im Grundsatz versteht und tool-unabhängig sicher anwenden kann."
Simona Hübl
CEO Nejo
Data Engineering ist mit 39,7 Prozent das Rückgrat des österreichischen Daten- und KI-Arbeitsmarktes – und damit prozentual sogar stärker ausgeprägt als im deutschen Vergleichsmarkt (36,4 Prozent). Vor der Wertschöpfung durch KI-Modelle muss die Dateninfrastruktur stehen; dieser "Picks-and-Shovels"-Layer dominiert die aktuelle Nachfrage in Österreich besonders deutlich. MLOps & Platform Engineering (28,0 Prozent) bestätigt, dass der Markt vom Modellbau zum Modellbetrieb übergegangen ist.

Azure führt vor AWS – eine bemerkenswerte Umkehrung des in den meisten europäischen Märkten zu beobachtenden AWS-Vorsprungs. Österreichs Daten- und KI-Markt ist Microsoft-orientiert: geprägt von Banken, SAP-zentrierten Beratungshäusern und Enterprise-Software-Anbietern, die den Microsoft-Stack als bevorzugte Cloud-Plattform wählen. Google Cloud bleibt auf einem klaren dritten Platz; Vertex AI mit lediglich 3 Nennungen zeigt, dass Googles KI-Plattform im untersuchten Stellensegment noch nicht etabliert ist.
Im Profil der Data Engineers (32 Stellen) erscheint Microsoft Fabric mit 11 Nennungen unter den Top-Werkzeugen – vor Google Cloud Platform (7), Azure (6) und Snowflake (5). Microsoft Fabric ist Microsofts integrierte Data-Plattform und schließt die Lücke zwischen klassischen BI-Werkzeugen (Power BI), Data Warehouses, Notebooks und Datenpipelines.
Die ausgeprägte Microsoft-Fabric-Adoption in Österreichs Data-Engineering-Stellenanforderungen ist eine Besonderheit gegenüber stärker AWS- oder Snowflake-zentrierten Märkten.

Die Architektur generativer KI-Anwendungen ist im österreichischen Stellenmarkt bislang vergleichsweise dünn besetzt. AI Tools & Assistants als generelle Kategorie dominiert (93 Nennungen) – konkrete Tooling-Skills wie Prompt Engineering (16) und LangChain (5) sind noch im Aufbau. Vektordatenbanken (Pinecone, Weaviate, Milvus) erscheinen jeweils nur in Einzelfällen.
Die generische LLM-Kompetenz dominiert auch in Österreich gegenüber jedem einzelnen Anbieter – Arbeitgeber spezifizieren in Stellenanzeigen Fähigkeiten, nicht Marken. Bemerkenswert ist die Position von GitHub Copilot auf Rang 2 (22 Nennungen), noch vor den OpenAI-Modellen selbst (14). Die Microsoft-Affinität des österreichischen Marktes zeigt sich auch im LLM-Werkzeugsegment.
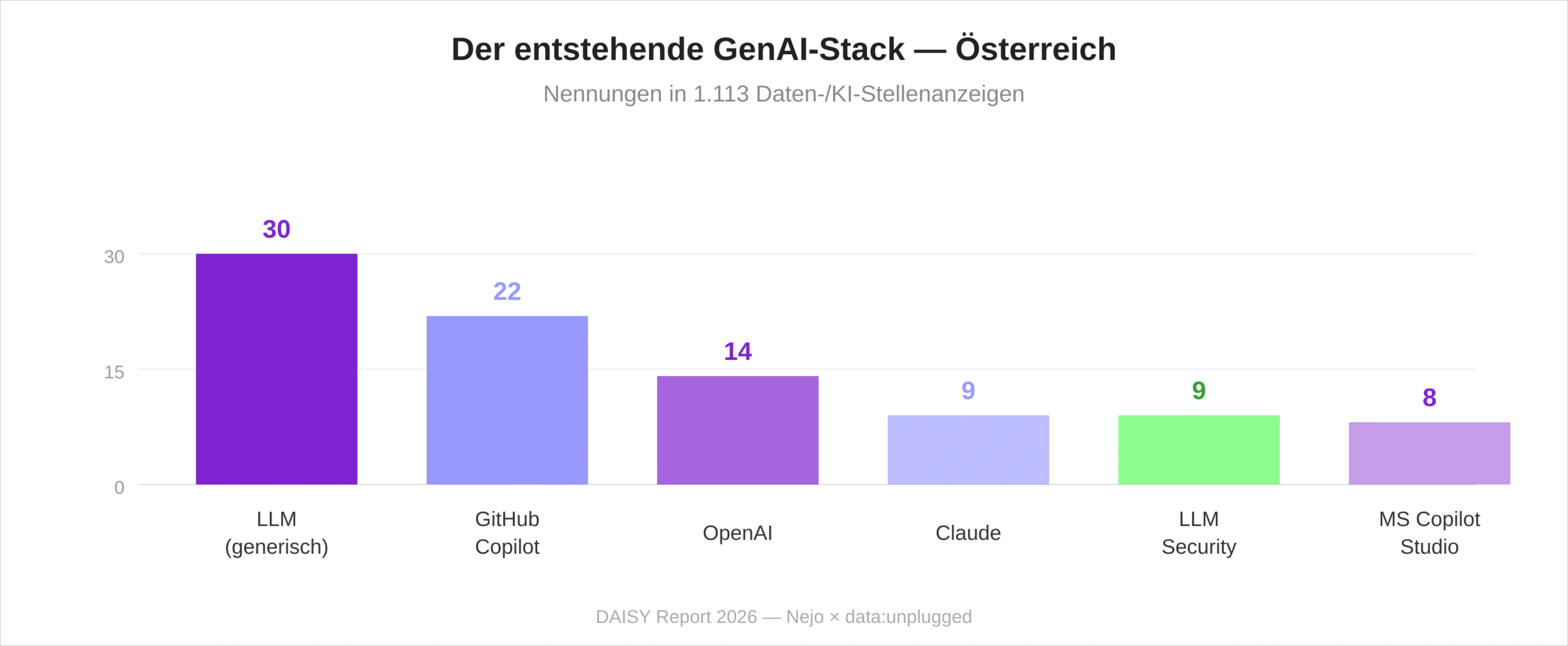
9 Nennungen für LLM Security als eigenständige Kompetenz markieren bereits in einem kleineren Datensatz eine erkennbare Nachfrage nach Sicherheitsexpertise für generative KI-Systeme. Der Aufbau dieser Disziplin parallel zur LLM-Adoption deutet darauf hin, dass die LLM-Integration in Österreichs Unternehmen zumindest in Teilbereichen über die Experimentierphase hinaus ist.
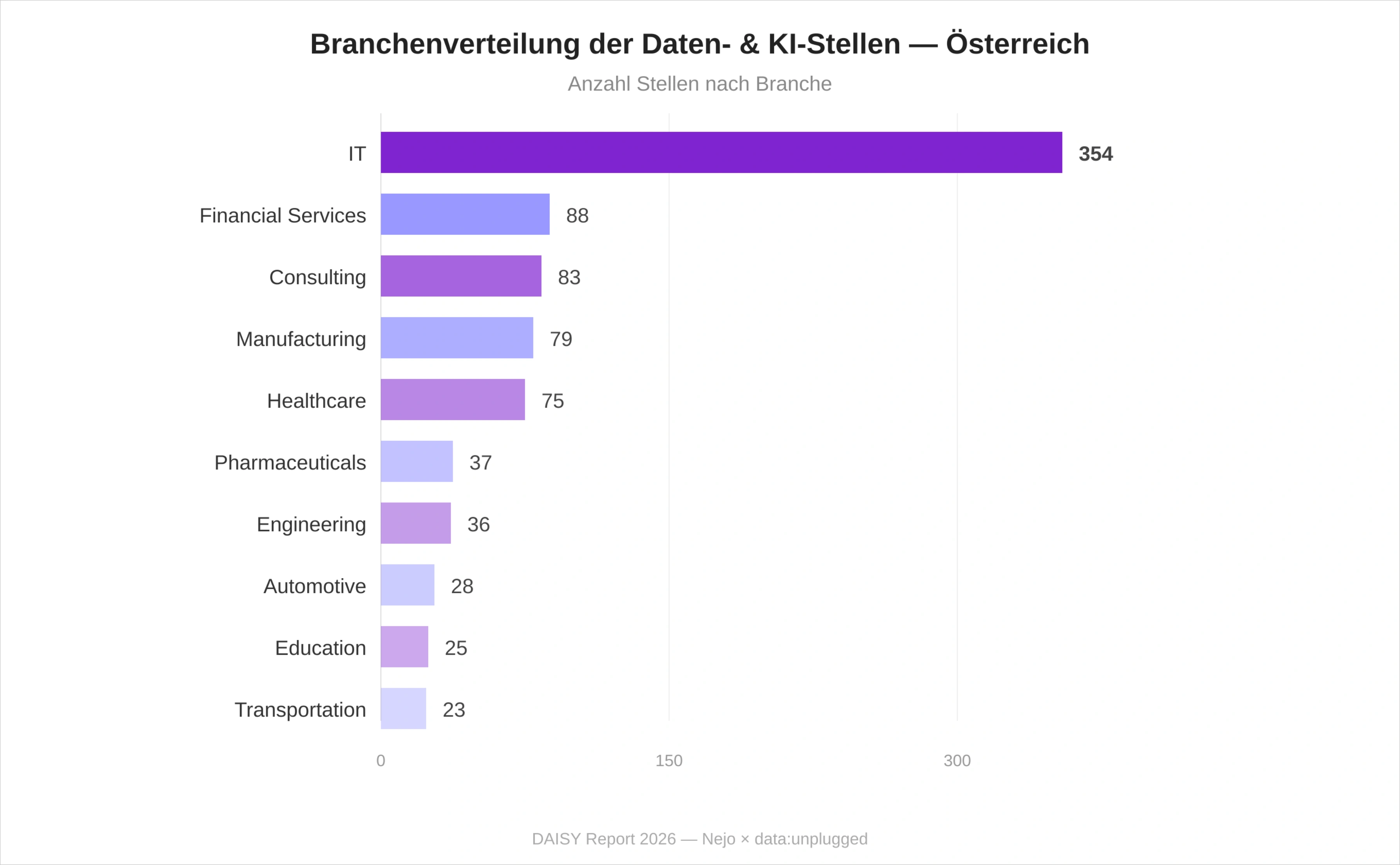
Die IT-Branche stellt mit 354 Stellen den größten Einzelblock – dreimal so viele Daten- und KI-Stellen wie die zweitgrößte Branche. Daneben prägen ein Financial-Services-Cluster (88 Stellen, getragen von Raiffeisen, Erste, BAWAG), ein Beratungs-Cluster (83 Consulting-Stellen) und ein Manufacturing-/Pharma-Cluster (79 + 37 Stellen) die Daten- und KI-Nachfrage außerhalb der reinen IT. Healthcare (75) und Pharmaceuticals (37) reflektieren Österreichs Position als Standort medizinisch-pharmazeutischer Forschung (Boehringer Ingelheim RCV, Sandoz, Novartis).
Besonders deutlich wird das in den Banken: In der Finanzbranche, die nach der IT die meisten offenen Daten- und KI-Stellen ausweist, verlangen Ausschreibungen zunehmend Databricks und sogar DORA-Metriken zur Messung der DevOps-Reife.
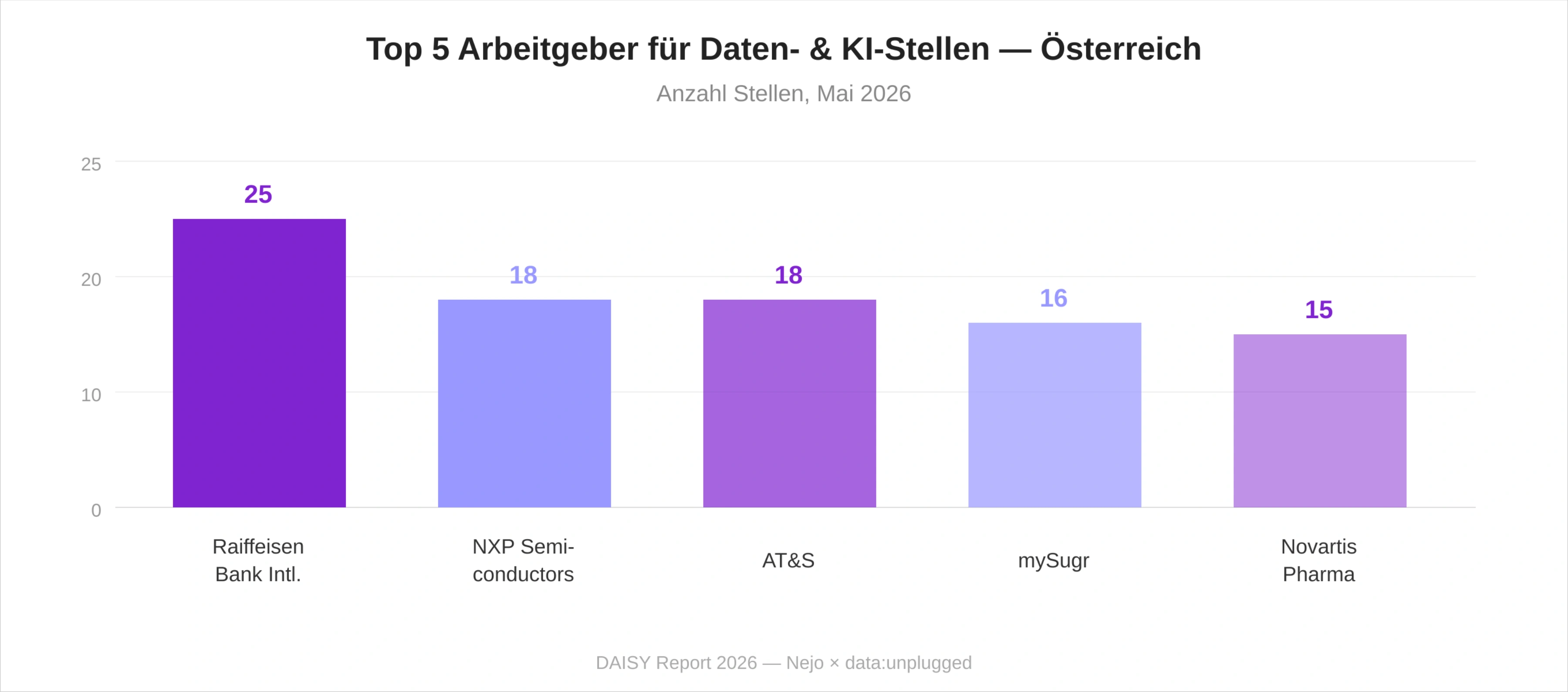
495 Unternehmen sind im untersuchten Datensatz mit mindestens einer offenen Daten- oder KI-Stelle vertreten. Die Daten- und KI-Nachfrage ist also durchaus breit über viele Arbeitgeber verteilt: Die fünf größten zusammen stellen rund 8,3 Prozent aller analysierten Stellen – eine etwas stärker ausgeprägte Spitzengruppe als in Deutschland (5,7 Prozent), aber weiterhin keine Konzentration auf einzelne Großarbeitgeber.
Die Spitzenposition von Raiffeisen Bank International ist strukturell signifikant: Der größte Nachfrager nach Daten- und KI-Fachkräften in Österreich ist eine Bank, nicht etwa ein Technologieunternehmen. Anders als in den USA oder Großbritannien verfügt Österreich nicht über Tech-Konzerne in der Größenordnung eines Google, Microsoft oder Amazon; die Daten- und KI-Nachfrage in der Spitzengruppe wird daher von Banken (Raiffeisen, Erste), Halbleiter- und Elektronik-Unternehmen (NXP, AT&S, später auch Infineon), Pharma (Novartis) und einzelnen heimischen Tech-Champions (mySugr) getragen. Im erweiterten Top-Feld (Rang 6–10) erscheinen mit KPMG (14), Erste Group (14), Red Bull (13), Deloitte (11) und PwC (11) zwei Beratungshäuser, eine weitere Bank, ein Konsumgüterkonzern und eine Wirtschaftsprüfungsgesellschaft.
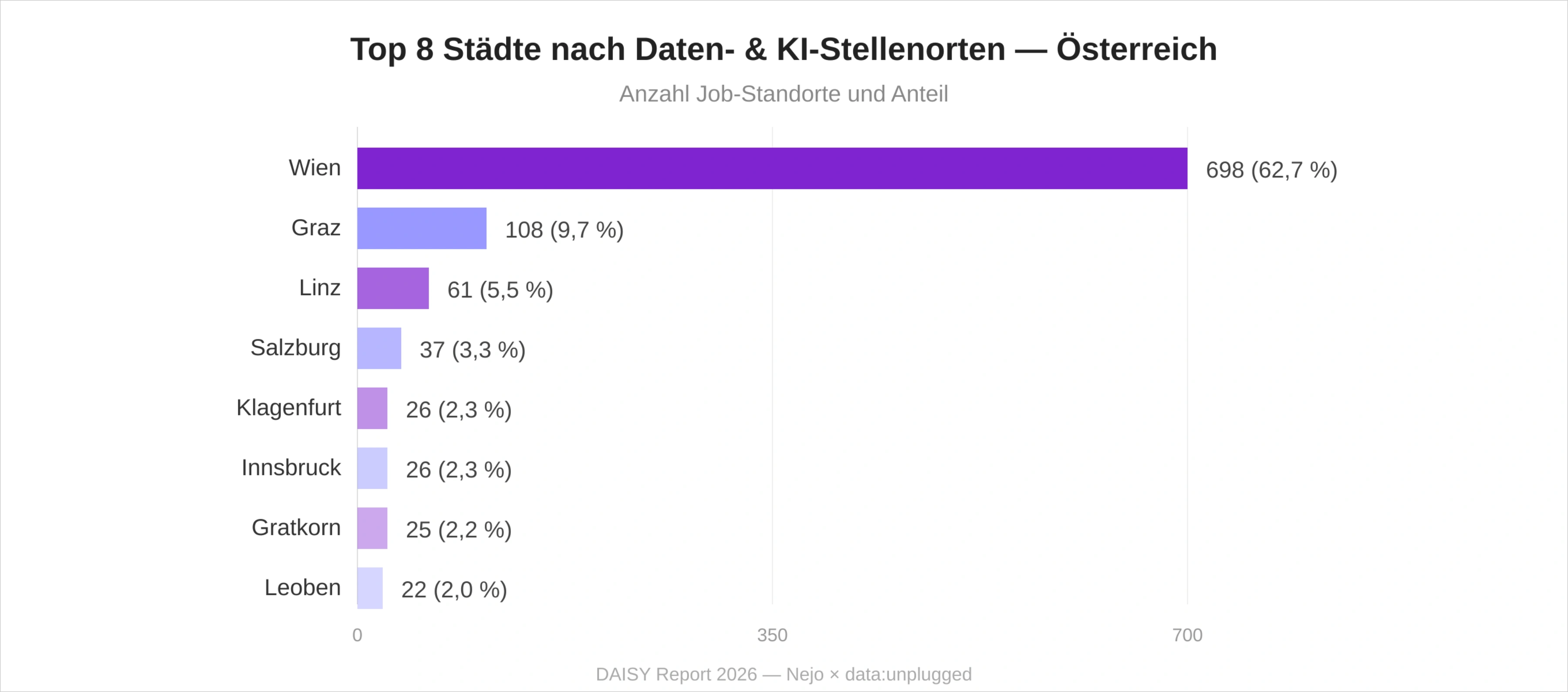
Wien (698) führt mit weitem Abstand: Mehr als 62 Prozent aller Daten- und KI-Job-Standorte liegen in der Bundeshauptstadt. Graz (108) folgt als zweitgrößter Standort, vor Linz (61) und Salzburg (37). Bemerkenswert ist die Präsenz steirischer Industrieorte wie Gratkorn (25, Mondi-Papierfabrik mit Industrie-4.0-Initiativen) und Leoben (22, Montanuniversität) in der Top 8 – ein Hinweis auf die hohe Daten- und KI-Adoption in industriellen Spezialstandorten.
Die kompetenzdichtesten Standorte sind nicht die größten: Graz weist die höchste Skill-Intensität auf – mit durchschnittlich 5,3 DAISY-Skills pro Stelle deutlich vor Wien (4,6). Während Wien das Stellenvolumen dominiert, fordern Grazer Stellenanzeigen pro Posting deutlich breitere Skill-Stacks. Volumen und Tiefe sind verschiedene Marktsignale für ein Standortbild.

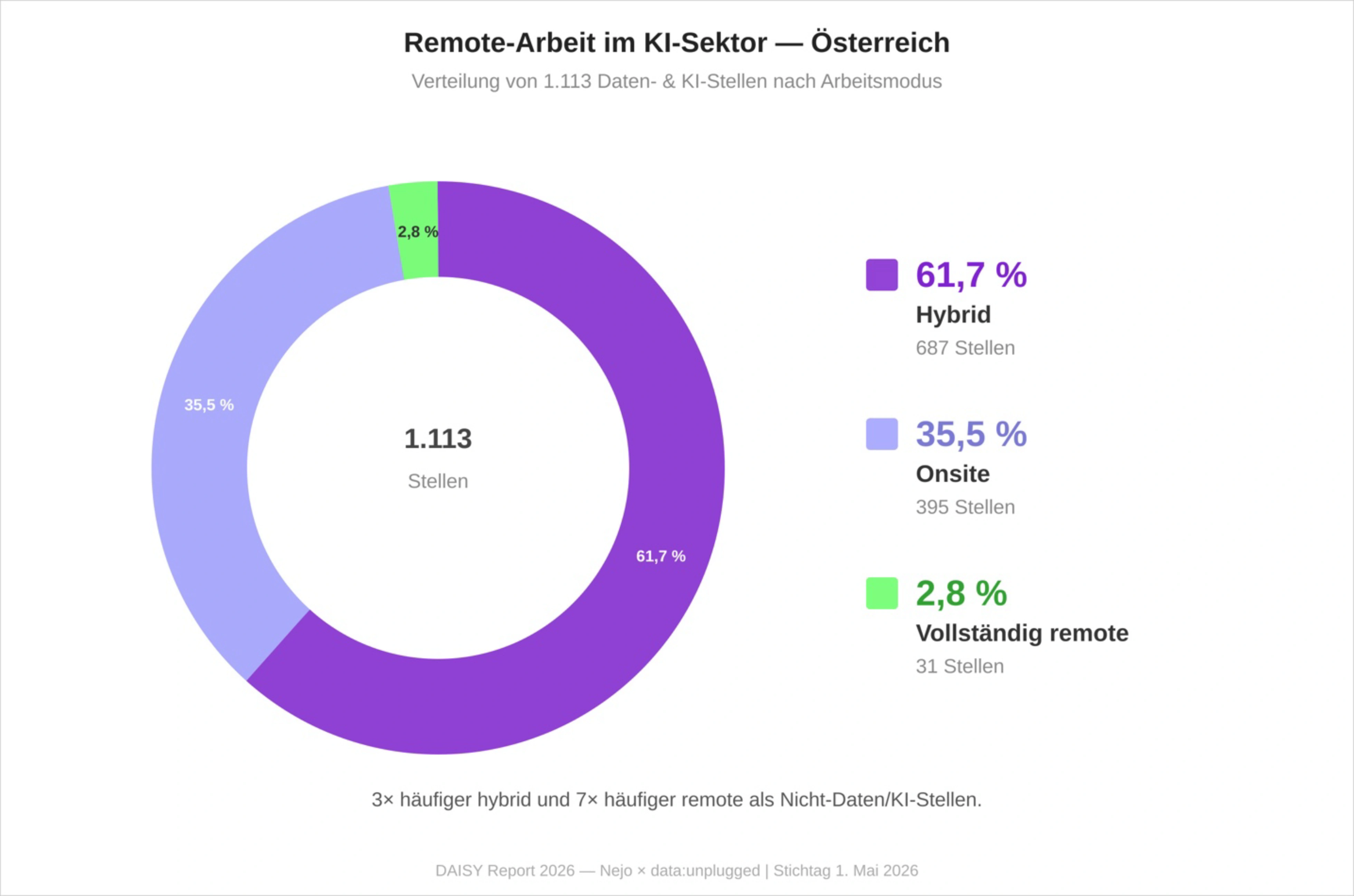
Fast 6 von 10 Daten- und KI-Stellen werden mit der Möglichkeit zur Arbeit auch im Home-Office angeboten. Vollständige Remote-Arbeit bleibt mit 2,8 Prozent die Ausnahme. Im Vergleich zum Gesamtarbeitsmarkt sind Daten- und KI-Stellen dreimal so häufig hybrid und siebenmal so häufig vollständig remote wie der durchschnittliche Nicht-Daten/KI-Job in der Datenbasis. Flexibilität ist im Wettbewerb um KI-Fachkräfte also ein wichtiges Differenzierungsmerkmal.
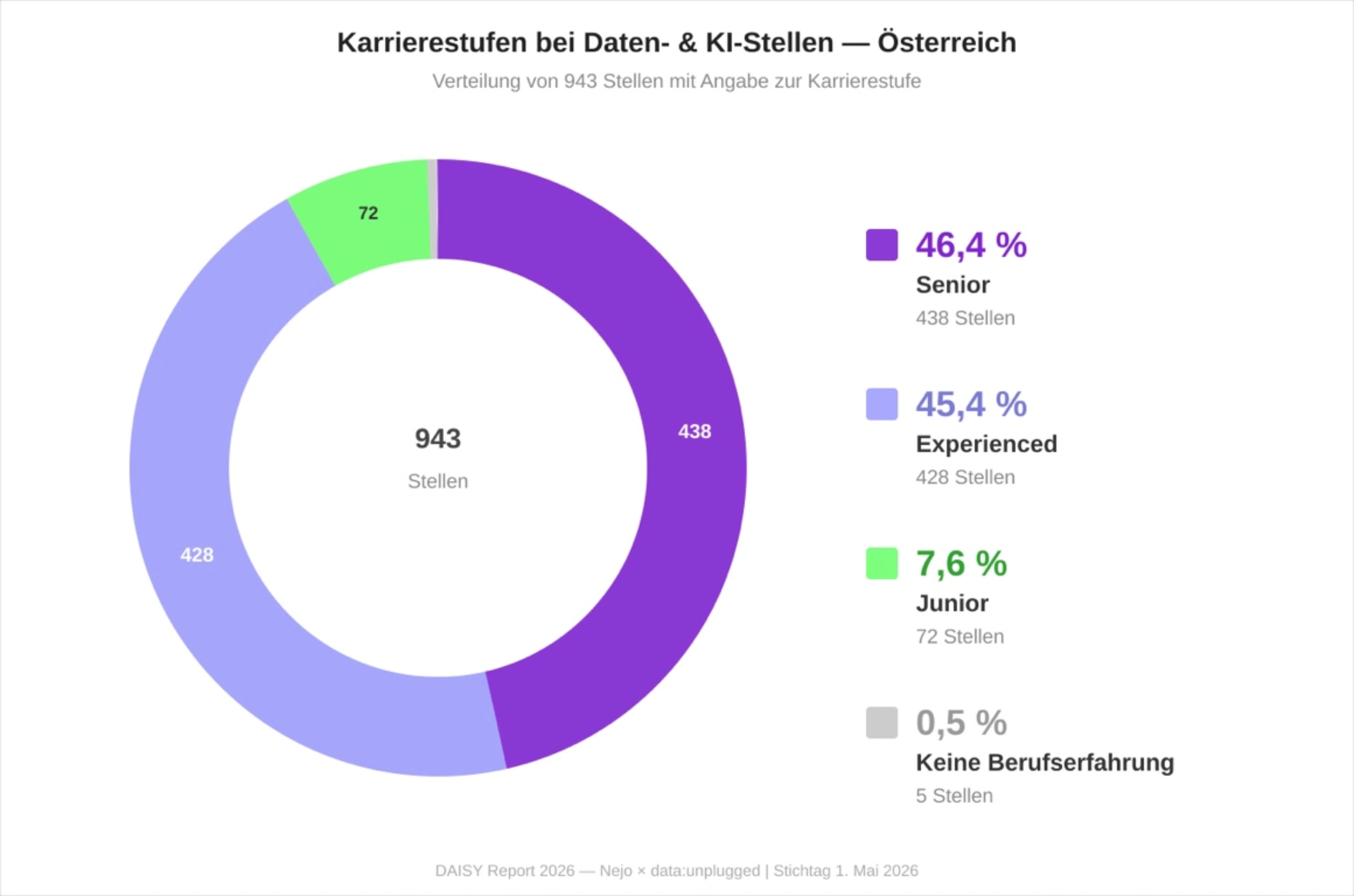
77,9 Prozent aller mit Karrierestufe ausgeschriebenen Daten- und KI-Stellen richten sich an Senior- oder Experienced-Profile. Junior-Stellen machen 6,5 Prozent aus, Berufseinsteigerstellen ohne Erfahrungsvoraussetzung lediglich 0,4 Prozent. Die Nachfrage konzentriert sich damit klar auf bereits berufserfahrene Profile – Einstiegspositionen sind die strukturelle Ausnahme.
28,5 Prozent der Daten- und KI-Stellen verlangen kein Deutsch – ein hoher Anteil, der die Internationalisierung des österreichischen Daten- und KI-Markts unterstreicht. Wien als Sitz internationaler Konzernzentralen, multinationaler Organisationen (UNO, OPEC, OSZE) und einiger Tech-Hubs treibt diesen Anteil. Lediglich 19,0 Prozent der Stellen verlangen ausschließlich Deutschkenntnisse – ein im DACH-Vergleich niedriger Wert.
Der Bachelor-Abschluss ist die häufigste Bildungsanforderung. Bemerkenswert ist die hohe Zahl an Stellen mit Berufsausbildung als ausreichender Qualifikation (442 Stellen, 39,7 Prozent) – Österreichs duales Bildungssystem fungiert als substanzieller Eingang in den Daten- und KI-Arbeitsmarkt. Die niedrige Master-Anforderung (60 Stellen, 5,4 Prozent) und der noch geringere Anteil expliziter Promotions-Anforderungen (PhD: 9 Stellen, 0,8 Prozent) zeigen: Auch bei großzügiger Auslegung ist der untersuchte Daten- und KI-Stellenmarkt nicht hochakademisiert – Praxisqualifikation und Bachelor-Abschluss werden in der überwiegenden Mehrheit der Stellen als ausreichend angesehen.
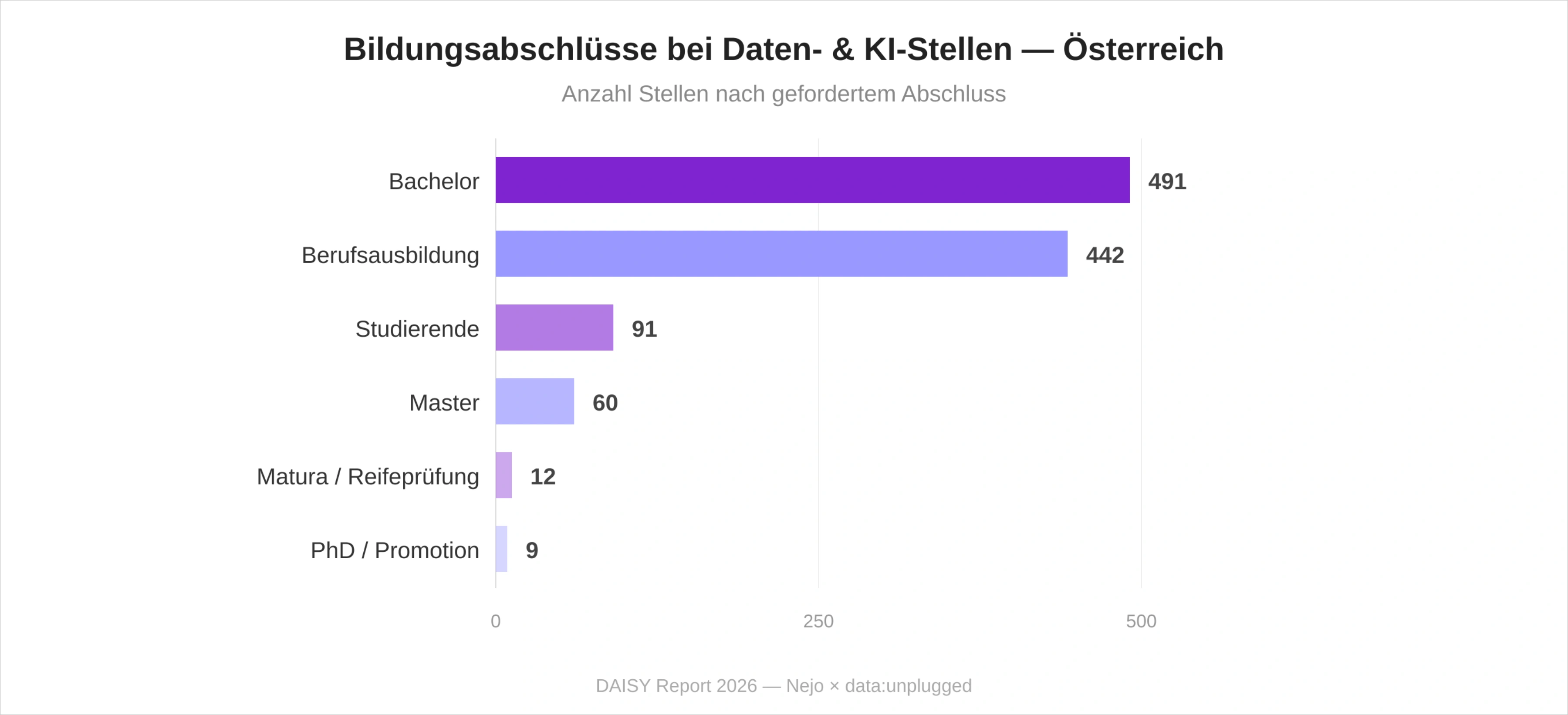
Die kleinste, aber strategisch bedeutsamste Zahl dieser Studie ist 72 – die Anzahl der ausgeschriebenen Junior-Stellen im österreichischen Daten- und KI-Sektor. In einem Markt von 1.113 Stellen entspricht das einem Anteil von 6,5 Prozent an der Gesamtnachfrage, beziehungsweise 7,7 Prozent der mit Karrierestufe spezifizierten Stellen.
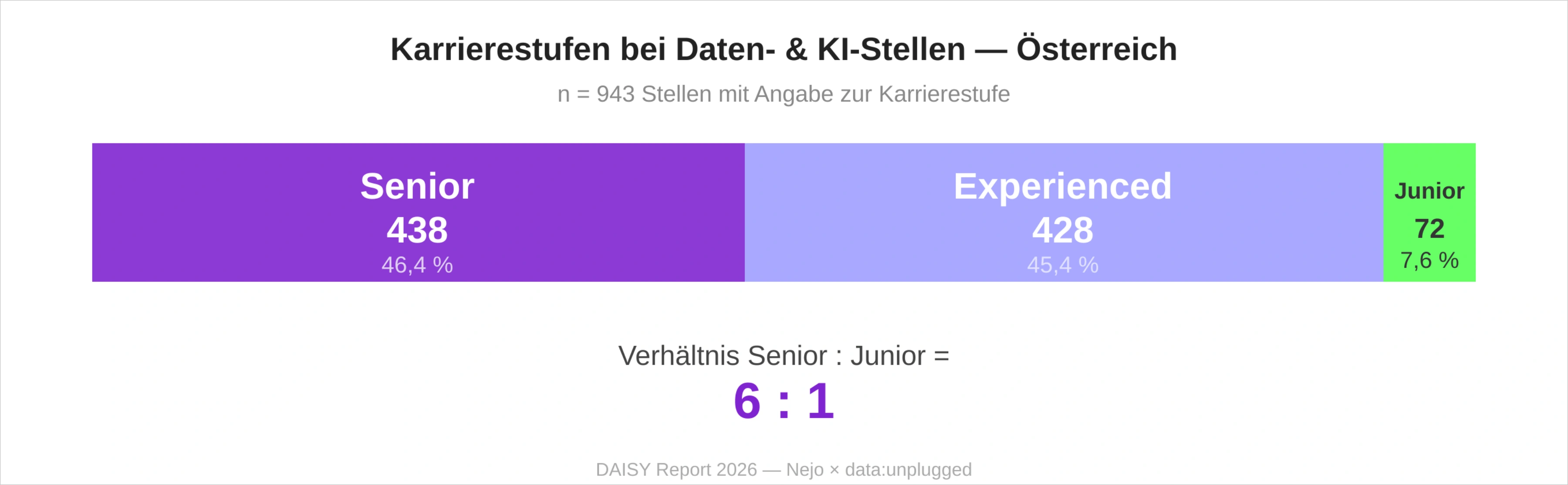
Die österreichische Wirtschaft konsumiert in großem Stil erfahrene Daten- und KI-Fachkräfte, baut aber die eigene Nachwuchspipeline nur in geringem Umfang aus. Das Verhältnis von Senior- zu Junior-Stellen liegt bei über 6:1 – ein Indikator dafür, dass die nächste Generation von KI-Fachkräften überwiegend extern rekrutiert oder importiert werden muss. Sofern sich die Junior-Quote nicht erhöht, verschiebt sich der gegenwärtige Mangel an erfahrenen KI-Fachkräften in drei bis fünf Jahren auf die nächste Kohorte.
"Die österreichische Wirtschaft sucht erfahrene KI-Fachkräfte in großem Stil – baut die eigene Nachwuchspipeline aber kaum auf. Wenn wir die Junior-Quote nicht erhöhen, verschieben wir den heutigen Fachkräftemangel in drei bis fünf Jahren auf die nächste Kohorte – und müssen die nächste Generation importieren, statt sie im Land auszubilden."
Maximilian Fischer
Head of Business Development data:unplugged
Die hohe Akzeptanz von Berufsausbildungen (442 Stellen) deutet darauf hin, dass formelle akademische Hürden nicht das primäre Hindernis sind. Die Einstiegsbarriere liegt vielmehr im Mangel an explizit als Einstieg ausgewiesenen Stellen. Eine politische und unternehmerische Aufwertung von Junior-, Trainee- und Lehrlingsprogrammen für Daten- und KI-Kompetenzen könnte hier ein wirksamer Hebel sein.
Für die Datenerhebung kam ein eigens entwickelter Web-Crawler zum Einsatz, der Stellenanzeigen direkt von Unternehmenswebseiten extrahiert. Externe Jobplattformen, Vermittlungsdienste und Aggregatoren wurden bewusst nicht einbezogen. Dadurch entsteht ein duplikatarmer Datensatz, der vorrangig primäre Arbeitgeberbedarfe abbildet.
Der Report basiert auf einer Analyse von 24.892 Stellenanzeigen, die am Stichtag 1. Mai 2026 in der Nejo-Datenbasis für Standorte in Österreich verzeichnet waren. Von diesen wurden 1.113 (rund 4,5 Prozent) als Daten- oder KI-Stelle klassifiziert. Die Klassifikation erfolgte KI-gestützt anhand der in der Stellenanzeige beschriebenen Aufgaben – nicht allein anhand des Stellentitels oder einzelner geforderter Werkzeuge.
DAISY (Data & AI Skills Ontology) ist eine domänenspezifische Skills-Ontologie für Daten- und KI-Kompetenzen – gemeinsam entwickelt von Nejo und data:unplugged. Sie umfasst derzeit 525 granulare Skills und schließt eine spezifische Lücke europäischer Klassifikationssysteme: Der ESCO-Standard ist europaweit etabliert für die übergeordnete Skill-Klassifikation, bildet die rasante Entwicklung daten- und KI-spezifischer Kompetenzen (etwa MLOps, Prompt Engineering, dbt oder Retrieval-Augmented Generation) jedoch nicht ausreichend granular ab. DAISY folgt einer vierstufigen Hierarchie (Domain, Discipline, Capability, Skill) und ist als SKOS-Datenmodell aufgebaut, wodurch es sich über einen SKOS-Crosswalk in ESCO-kompatible Systeme integrieren lässt.
Im Report findest du alle Charts, die vollständige Methodik und viele Detailauswertungen, die hier keinen Platz hatten. Er soll Arbeitgeber:innen, Arbeitnehmer:innen und Bildungsanbietern helfen, den österreichischen Daten- und KI-Arbeitsmarkt besser zu lesen. Darum stellen wir ihn kostenlos zur Verfügung.
Du brauchst ganz bestimmte Auswertungen oder Daten für deine Branche? Schreib uns einfach unter hi@mynejo.com.
Dieser Beitrag wurde das erste Mal am veröffentlicht. Letztes Update am .

